One of my banking clients has a large SQL Server farm which hosts support data. Another client uses SharePoint as ECM (Enterprise Content Management) system which relies on underneath SQL Server farm. Both are dependent on the infrastructure operating 24*7*365, both have strong needs to monitor the performance of SQL Server farm.
Let’s see how to build performance monitoring layers for a SQL Server farm. Though this might not be the best approach, it can be a great reference based on technical implementation feasibility under existing IT environment.
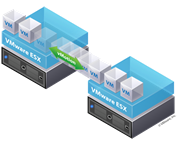
A picture is worth a thousand words. Let’s assume that we utilize NetApp as storage, VMware ESXi (vs. Hyper-V) as bare-metal OS. The guest OS is Windows Servers on which SQL Server instances run. As illustrated, scale-out (vs...
Read More