Confluent is a streaming platform based on Apache Kafka. Apache Kafka is a distributed streaming platform which offers three key capabilities: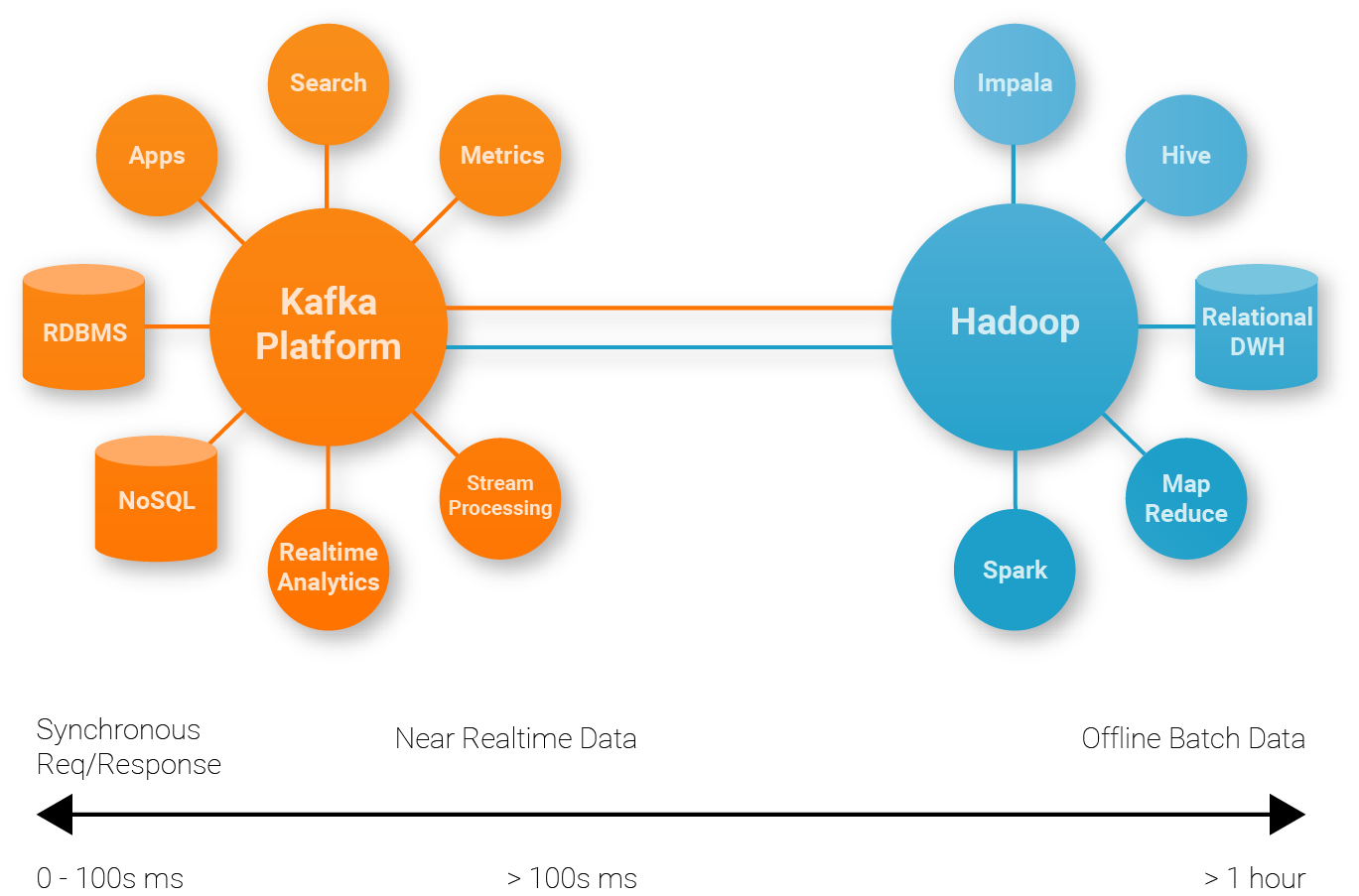
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
- It lets you store streams of records in a fault-tolerant way.
- It lets you process streams of records as they occur.
So Kafka is good for:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
Now let’s get back to Confluent. Confluent offers Confluent Open Source and Enterprise editions. We may see Confluent a wrapper of Apache Kafka. Confluent Open Source comes with Apache Kafka, additional clients such as C, C++, Python, .NET, etc., REST proxy and pre-built Connectors. Confluent Enterprise includes all what Confluent Open Source has, plus UI Confluent Control Center, Auto Data Balancer and Replicator, etc. Please refer to the comparison to understand more of the differences between Kafka, Confluent Open Source and Enterprise.
Most users will start from Confluent Open Source. Since it wraps Apache Kafka nicely, plus it adds valuable pre-built Connectors.
Confluent Connectors can be classified into two types: Source and Sink. Source Connectors interface with message producers and import data into Zookeeper; Sink Connectors interface with message consumers and export data from Zookeeper. A bunch of enthusiastic companies, including Microsoft, Oracle, IBM, SAP, HP, …, provided connectors for their own data stores, to make sure people may use their systems with Apache Kafka seamlessly. Confluent offers a few connectors, including JDBC Source and Sink, Amazon S3 Sink, HDFS Sink, etc. Here’s a full list of Confluent Connectors.
Essentially, Confluent offers as a message broker system, to provide:
- At-most-once (zero or more deliveries);
- At-least-once (one or more message deliveries, duplicate possible);
- Exactly-once (one and only once message delivery).
But with what the platform offers and these rich Confluent Connectors, to build up an Exactly-once data synchronization pipeline is not a dream. The best is to utilize existing Connectors to interface with Big Data and NoSQL data stores. Stay tuned to find more exciting news from us.
Should you want to understand more of Apache Kafka and Confluent Platform, please let us know.
