During past two decades, I have been working on many database design and migration projects. There are a lot of decisions to make in creating new database schema. Any database schema changes can be very expensive in a later date. Some may even result in rewriting the front end applications. So to understand a few best practices and apply them in your database schema design is vital important.
1. Take the advantages of UML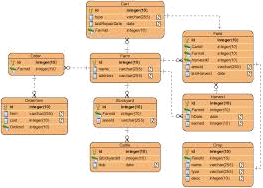
Most people use ERWin to create ERD, then use forward engineering to build up database schema. If we may move further and think about how to use object-oriented UML to describe the world, it might be very helpful. UML brings lots of benefits like composition relationship and inheritance (generalization relationship). Using composition relationship helps us to understand the relationship among objects deeper. There are quite a few tools available on the market. Visual Paradigm is one of the best tools to help us design database schema in UML. To learn more, please refer to another blog article Database Modeling in UML.
2. Use meaningful PK and FK name style
The name style of PK and FK is quite important since we understand the relationship between two or more entities (in ERD) or objects (in UML) based on them. For instance, if I have a table road with a PK objectid, then another table bridge (on this road) should have a FK called roadoid, which means it points to road.objectid. If we follow this name style in the entire schema design, it will make it simple, elegant and easy to understand.
3. Use Integer PK, try to avoid multi-column PKs
If it’s possible, we need to avoid multi-column PKs, instead, to use integer PK makes things a lot easier. Consider an entity an object, each object has a unique identifier — its PK. If you use UML to build up the database schema, then the whole thing will be a lot easier. In an abstract class, we have an objectid field which can be inherited by all other objects. This means later on, each database table has an objectid as its PK.
4. Use name convention to build a well-structured schema
To make things easy to understand and manage, we naturally group relevant objects together. This leads to create modular-based, well-structured schema.
a. Group relevant table together
Most of the database client tools, such as TOAD, SQL Developer, have a table list in a tree view. Name convention allows relevant database tables stay together for unified manipulation and management. A prefix with an underscore is a typical way to use name convention. For instance, a table for Silviculture Information System may have ‘sis_’ as its prefix. Anyone who sees this table knows it’s for Silviculture Information System.
b. Identify data table and lookup table
A database schema consists of main data tables and lookup tables (validation tables). We want to identify them by name convention as well. The reason is data table contains more fields and needs ‘design’ while lookup table has simple and almost unified structure. For instance, if we name main data tables using ‘sis_survey’, then we may name lookup table using ‘sis_vt_surveytype’. By reading the name, we know the lookup table is for field sis_survey.type.
c. Identify data table and view
As many reports are based on view, it would be nice to identify data table and view as well. For instance, if we have a view created on the base table sis_survey, it can be called v_sis_survey. Once we see it, we know it’s based on sis_survey, it’s easy to trace back to its data source, also we know we may expand this view fields.
5. Use descriptive table and column names
To use descriptive and meaningful table and column names are always important. Underscore is a good separator in table name and column name to make the entire schema easy to read. We want to avoid abbreviated words like ‘mgmt’ if possible.
6. Use prefix instead of suffix
In most cases, we prefer prefix. The reason is it allows relevant tables group together, makes grant privilege to a group relevant tables or views a lot easier.
7. Maintain unified table structure
To maintain the table structure similar is also very important. For instance, we want to have PK objectid always sit as the first column, other columns sit in their according positions, audit trail columns always sit at the end of each data table and lookup table. It will make the whole schema easy to read and understand.
8. Maintain single source of truth
I have seen a bad database schema which contains multiple versions of one data table, for instance, exp3_examlist, exp4_examlist, exp4_examlist1. This is a disaster. After checking around, I started to know exp3 is for version 3 of the application, the exp4 is for version 4 of the application; what’s the usage of examlist and examlist1, only God knows. We should maintain a particular data table as the single source of truth, straight forward, simple and clear. We really want to avoid having multiple versions of one data table. If it’s the case, you really need to re-think how you want to design your schema.
9. Implement audit trail in event tables
I have a client who encountered bad performance issue in generating reporting in his system. When I look at his legacy database schema, I noticed that there’s a transaction table which contains all the audit trail information (modifiedby, modifiedon, modifiedusing, createdby, createdon, createdusing) for all activities and events. Any revisions that user made are recorded in this transaction table. In first few years, the system runs normally. But after 5 years, any query related to this transaction table takes more than 20 minutes. The reason is this table has grown too big, occupied more than half of the spaces of the entire database. At the end, the entire schema has to be redesigned to address the performance issue. The solution is to include all the audit trail fields in each activity tables.
10. Consider Metadata Management (MDM) through out the design phase
It’s not one time we get confused that where the reporting data come from. There are so many same name fields in different tables. This involves metadata management. There’s no better way to manage metadata than building up a business glossary (enterprise vocabulary) and tracing down relevant fields from conceptual model, logical model, physical model to BI reports. We should also pay extra cautions on metadata management in data integration and migration procedures.
If you are looking for data architectural design or data modeling, please refer to Data Modeling. If you are looking for data analysis or data migration, please refer to Data Analysis & Migration. If you are looking for Data Warehouse and BI solution, please refer to Data Warehouse & BI.
