We talked how to track database changes with one auditing table last month. If we want to replicate these changes into another database, then we might use multi-threading to gain the high performance in data ingestion. However, based on our previous design, we track changes to column level, which generates a serious concurrency control issue. Let’s think about, we have a data table, 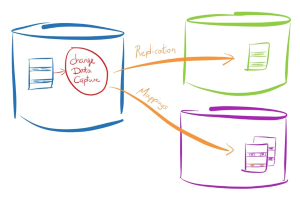 with 10 columns updates at once, then all these changes are captured and inserted into my_audit_table. If at the same time, another table gets updated, then there might have some cross inserting in my_audit_table, which makes the multi-threading read even harder.
with 10 columns updates at once, then all these changes are captured and inserted into my_audit_table. If at the same time, another table gets updated, then there might have some cross inserting in my_audit_table, which makes the multi-threading read even harder.
Is there a better approach that we should go? In this case, it’s worth to re-design the audit_table. Let’s see how it looks like (in Oracle PL/SQL):
c...Read More